
Page 18 - IPP-12-2025
P. 18
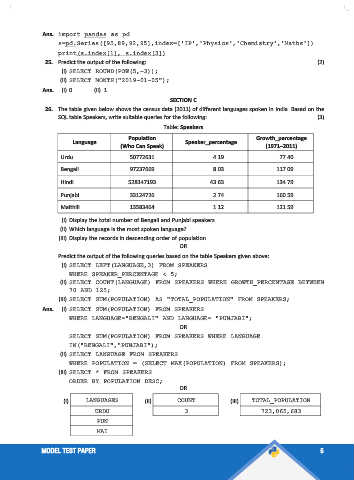
17. Fill in the blank. [1]
To find the number of rows and columns of a dataframe, attribute is used.
(a) shape (b) size
(c) ndim (d) count()
Ans. (a) shape
18. Which plot is best used to visualize categorical data distribution in Matplotlib? [1]
(a) Pie chart (b) Bar plot (c) Line plot (d) Histogram
Ans. (b) Bar plot
19. Wi-Fi is an example of which of the following network types? [1]
(a) PAN (b) MAN (c) LAN (d) WAN
Ans. (c) LAN
Questions 20 and 21 are Assertion and Reasoning Based Questions. Mark the correct choice as
(a) Both Assertion (A) and Reason (R) are true and Reason (R) is the correct explanation for Assertion (A).
(b) Both Assertion (A) and Reason (R) are true but Reason (R) is not the correct explanation for
Assertion (A).
(c) Assertion (A) is true but Reason (R) is false.
(d) Assertion (A) is false but Reason (R) is true.
20. Assertion (A): Pandas dataframes allow indexing using both labels and integer-based positions. [1]
Reasoning (R): Dataframe indices are immutable and cannot be changed after creation.
Ans. (c) Assertion (A) is true but Reason (R) is false.
21. Assertion (A): The SQL command DROP DATABASE is used to delete a database and all of its content. [1]
Reasoning (R): DROP DATABASE removes database from the system, including its tables, indexes and data.
Ans. (a) Both Assertion (A) and Reason (R) are true and Reason (R) is the correct explanation for Assertion (A).
Section B (7 × 2 = 14 Marks)
22. Write any two advantages of CSV file formats. [2]
Or
How does a dataframe object specify indexes to its data rows?
Ans. The two advantages of CSV file formats are as follows:
(i) It is a simple, compact and universal format for data storage.
(ii) It can be opened in popular spreadsheet packages like MS Excel, Calc, etc.
Or
Dataframe has two indexes—a row index can be specified using (axis = 0) and a column index can be
specified using (axis = 1).
23. What do you mean by cyber security? [2]
Ans. Cyber security is the combination of practices and best processes to ensure the security of networks,
computers, programs, data and information from attack, damage or unauthorized access.
24. Consider the string Cloud Computing Technologies. Write suitable SQL queries for the following: (2)
(a) Find the length of the string.
(b) Extract and display the first 10 characters from the string.
Ans. (a) Select length('Cloud Computing Technologies');
(b) Select substring('Cloud Computing Technologies', 1, 10);
25. Define web browser and web server. [2]
Or
What is the difference between Static and Dynamic Websites?
Ans. A web browser is a software which is used for displaying the content on web page. It is used by the client to
view websites. Examples of web browser are: Google Chrome, Firefox, Microsoft Edge, Safari, Opera, etc.
A web server is a software which entertains requests made by a web browser. A web server has different
ports to handle different requests from the web browser, e.g., FTP request is handled at port 110.
An example of web server is Apache.
Or
M.15 Informatics Practices with Python–XII
34